
Managed instances
This documentation details how the Cloud team at Sourcegraph internally handles the provisioning/creation/configuration/maintenance of managed instances.
Please first read the customer-facing managed instance documentation to understand what these are and what we provide.
For operation guides (e.g. upgrade process), please see managed instances operations. This page is intended to provide additional external-facing information.
- Managed instances
When to offer a Managed Instance
Managed instances offer a backup alternative for using Sourcegraph when a customer either can’t or, for some reason, won’t deploy Sourcegraph self-hosted.
See below for the SLAs and Technical implementation details (including Security) related to managed instances.
Please message #cloud for any answers or information missing from this page.
When offering customers a Managed Instance, CE and Sales should communicate and gather information for the following topics
- Customers are comfortable with security implication of using a managed instance
- Customers’s code host should be accessible publically or able to allow incoming traffic from Sourcegraph-owned static IP addresses. (Notes: we do not have proper support for other connectivity methods, e.g. site-to-site VPN)
Managed Instance Requests
Customer Engineers (CE) or Sales may request to:
- Create a managed instance - [Issue Template]
- After ruling out a self-hosted deployment and determining a managed instance is viable for a customer/prospect
- For new customers or prospects who currently do not have a managed instance.
- Suspend a managed instance - [Issue Template]
- For customers or prospects who currently have a managed instance that needs to pause their journey, but intend to come back within a couple of months.
- Tear down a managed instance - [Issue Template]
- For customers or prospects who have elected to stop their managed instance journey entirely. They accept that they will no longer have access to the data from the instance as it will be permanently deleted.
Workflow
- CE seeks Managed Instance approval from their regional CE Manager
- The Regional CE Manager will review the following criteria:
- Overall, is the deal qualified?
- Is it technically qualified? We have documented POC success criteria and the customer agrees to the criteria. We have documented the basic technical requirements of the customer (languages, repo types, security, etc.)
- If anything is non-standard, it must pass the tech review process
- If approved, then CE proceeds based on whether this is a standard or non-standard managed instance scenario:
- For standard managed instance requests (i.e., new instance, no scale concerns, no additional security requirements), CE submits a request to the DevOps team using the corresponding issue template in the sourcegraph/customer repo.
- For non-standard managed instance requests (i.e., any migrations, special scale or security requirements, or anything considered unusual), CE submits the opportunity to Tech Review before making a request to the DevOps team.
- Message the team in #cloud-devops.
- If denied, the CE/AE can appeal through the CE/AE leadership chain of command.
SLAs for managed instances
Support SLAs for Sev 1 and Sev 2 can be found here. Other engineering SLAs are listed below
| Description | Response time | Resolution time | |
|---|---|---|---|
| New instance Creation | Spin up new instance for a new customer | Within 24 hours of becoming aware of the need | Within 15 working days from agreement |
| Existing instance suspension | Suspend an existing managed instance temporarily | Within 24 hours of becoming aware of the need | Within 15 working days from agreement |
| Existing instance deletion/teardown | Decommission/delete and existing managed instance | Within 24 hours of becoming aware of the need | Within 15 working days from agreement |
| New Feature Request | Feature request from new or existing customers | Within 24 hours of becoming aware of the need | Dependenant on the request |
| Maintenance: Monthly Update to latest release | Updating an instance to the latest release | NA | Within 1 week after latest release |
| Maintenance: patch/emergency release Update | Updating an instance with a patch or emergency release | NA | Within 1 week after patch / emergency release |
Incident Response
Incidents which affect managed instances handled according to our incidents process.
Technical details
As of , new managed instances are using the v1.1 architecture, learn more
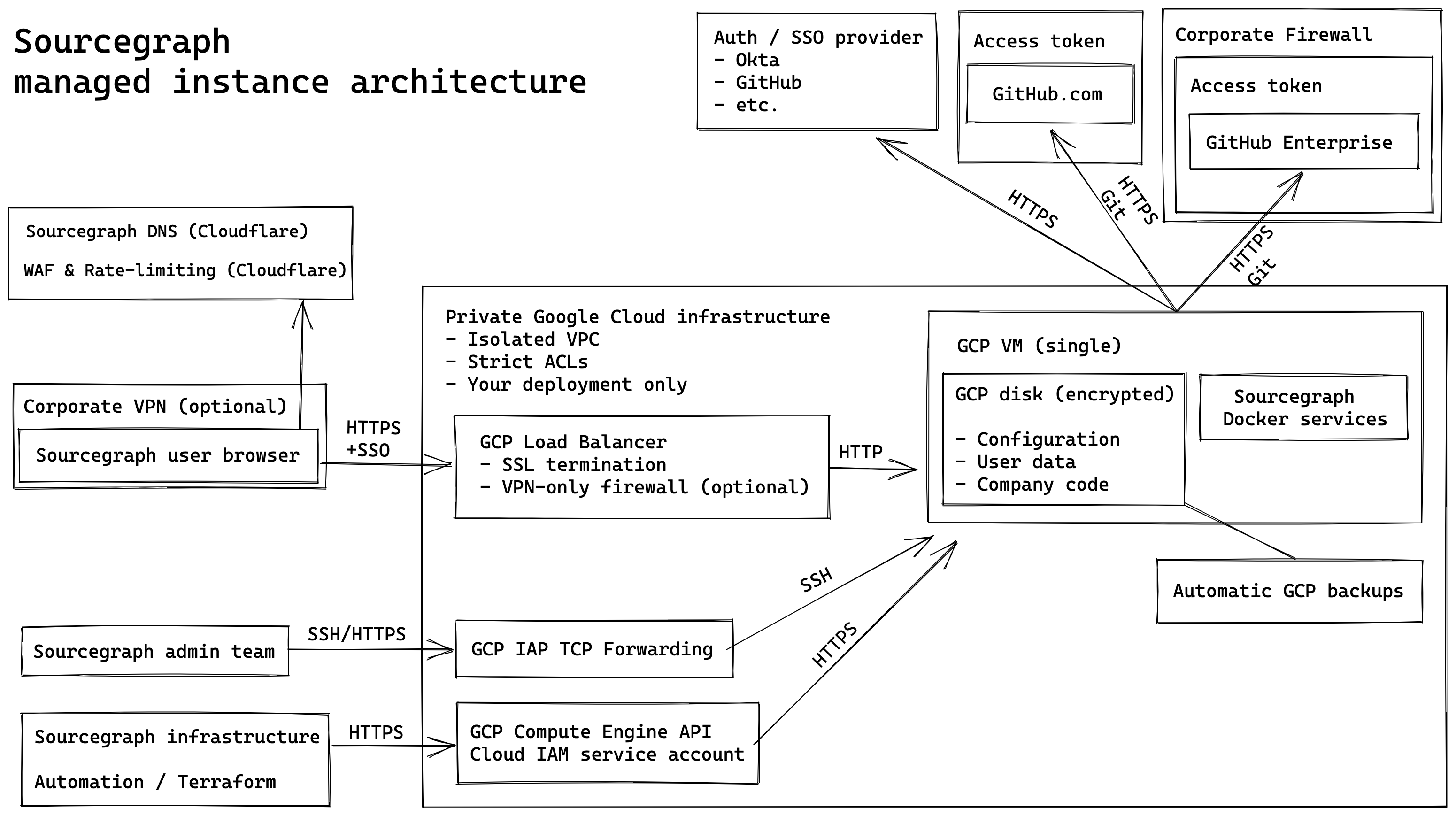
Deployment type and scaling
Managed instances are Docker Compose deployments only today. We do not currently offer Kubernetes managed instances.
These managed Docker Compose deployments can scale up to the largest GCP instance type available, n2-standard-128 with 128 CPU / 512 GB memory which is typically enough for most medium to large enterprises.
We do not offer Kubernetes managed instances today as this introduces some complexity for us in terms of ongoing maintenance and overhead, we may revisit this decision in the future.
Environments
SOC2/CI-100
Internal instances
For each type of Managed Instances (v1.0 and v.1.1), Sourcegraph maintains separate test environments:
- for v1.0 - dev instance
- for v1.1 - rctest instance
Internal instances are created for various testing purposes:
- testing changes prior to the monthly upgrade on customer instances. upon a new release is made available, DevOps team will follow managed instances upgrade tracker to proceed with upgrade process.
- testing significant operational changes prior to applying to customer instances
- short-lived instances for product teams to test important product changes. Notes: any teammate may request a managed instance through our request process
Customer instances
All customer instances are considered part of the production environment and all changes applied to these customers should be well-tested in the test environment.
Upgrade process to new Sourcegraph version is also preceded with upgrading test instances - upgrade to v3.40.1.
Release process
SOC2/CI-100
Sourcegraph upgrades every test and customer instances according to SLA.
The release process is performed in steps:
- New version is released via release guild
- Github issue in Sourcegraph repository is open based on the managed instances upgrade template
- Github issue is labeled with
team/devopsand Devops Team is automatically notified to perform Managed Instances upgrade. Label is part of the template. - DevOps team performs upgrade of all instances in given order:
- for Instances with version v1.0
- Test instances are upgraded - dev and demo
- Uptime checks are verified. This includes automated monitoring
- When test instances are working correctly, DevOps Team performs upgrade of all v1.0 customer instances
- for Instances with version v1.1
- Test instance is upgraded - rctest
- Uptime checks are verified. This includes automated monitoring
- When test instance is working correctly, DevOps Team performs upgrade of all v1.1 customer instances
Sample upgrade:
- tracking issue - 3.40.1.
- Github Pull Requests for 3.40.1 upgrade
Known limitations of managed instances
Sourcegraph managed instances are single-machine Docker-Compose deployments only. We do not offer Kubernetes managed instances, or multi-machine deployments, today.
With that said, Docker Compose deployments can scale up to the largest GCP instance type available, n1-standard-96 with 96 CPU & 360 GB memory, and are typically capable of supporting all but the largest of enterprises (around 25,000 repositories and 3,000 users are supported, based on what we have seen thus far.)
The main limitation of this model is that an underlying GCP infrastructure outage could result in downtime, i.e. is it not a HA deployment.
Security
- Isolation: Each managed instance is created in an isolated GCP project with heavy gcloud access ACLs and network ACLs for security reasons.
- Admin access: Both the customer and Sourcegraph personnel will have access to an application-level admin account.
- VM/SSH access: Only Sourcegraph personnel will have access to the actual GCP VM, this is done securely through GCP IAP TCP proxy access only. Sourcegraph personnel can make changes or provide data from the VM upon request by the customer.
- Inbound network access: The customer may choose between having the deployment be accessible via the public internet and protected by their SSO provider, or for additional security have the deployment restricted to an allowlist of IP addresses only (such as their corporate VPN, etc.)
- Outbound network access: The Sourcegraph deployment will have unfettered egress TCP/ICMP access, and customers will need to allow the Sourcegraph deployment to contact their code host. This can be done by having their code-host be publicly accessible, or by allowing the static IP of the Sourcegraph deployment to access their code host.
- Web Application Firewall (WAF) protections: The Sourcegraph deployment, if open to the Internet, will be proxied through Cloudflare and leverage security features such as rate limiting and the Cloudflare WAF. Notes: Cloudflare WAF is not applicable when inbound network access is restricted to an allowlist of IP addresses only.
Access can be requested in #it-tech-ops WITH manager approval.
Monitoring and alerting
SOC2/CI-86 SOC2/CI-25
Each managed instance is created in an isolated GCP project. System performance metrics are configured and collected in scoped project. All metrics can be seen in scoped projects dashboard.
Every customer managed instance has alerts configured:
- uptime check - version v1.0 configured in dedicated GCP managed instance project
- uptime check - version v1.1 configured in dedicated GCP managed instance project
- instance performance metric alerts configured in scoped project for all managed instances
- application performance metrics - configured in customer intance site-config.json via
mg cliduring instance creation
Alerting flow:
- When alert is triggered, it is sent to Opsgenie channel:
-
From Opsgenie, alert is sent to on-call DevOps and Slack channels (#opsgenie, #cloud-devops).
-
On-call DevOps has to decide, what is the alert type and if incident should be opened and follow the procedure to perform the incident. On-call DevOps should use managed instances operations to check, assess and repair broken managed instance.
-
When alert is closed via incident resolution, post-mortem actions has to be assigned and performed.
Opsgenie alerts Sample managed instance incident - customer XXX is down.
Configuration management
Terraform is used to maintain all managed instances. You can find this configuration here: https://github.com/sourcegraph/deploy-sourcegraph-managed
All customer credentials, secrets, site configuration, app and user configuration—is stored in Postgres only (i.e. on the encrypted GCP disk). This allows customers to enter their access tokens, secrets, etc. directly into the app through the web UI without transferring them to us elsewhere.
Operations
Please review the Managed Instances v1.0 operations guide for instructions.
Managed Instances v1.1 documentation can be found here
FAQ
FAQ: Can customers disable the “Builtin username-password authentication”?
Yes, you may disable the builtin authentication provider and only allow creation of accounts from configured SSO providers.
However, in order to preserve site admin access for Sourcegraph operators, we need to add Sourcegraph’s internal Okta as an authentication provider. Please reach out to our team prior disabling the builtin provider.
FAQ: How do I restart the frontend after changing the site-config?
If you are a Cloud teammate, follow the regualr operation playbook.
Are you a member of our CE & CS teams?
- Visit sourcegraph/deploy-sourcegraph-managed
- Locate the
slugof the customer instance from list of folders - Visit https://github.com/sourcegraph/deploy-sourcegraph-managed/actions/workflows/reload_frontend.yml
- Click
Run workflowand input theslugof customer instance - Click the
Run workflowgreen button - Done! It shoudln’t take more than 2 mintues